Avalon's Game of Thoughts: Battle Against Deception through Recursive Contemplation
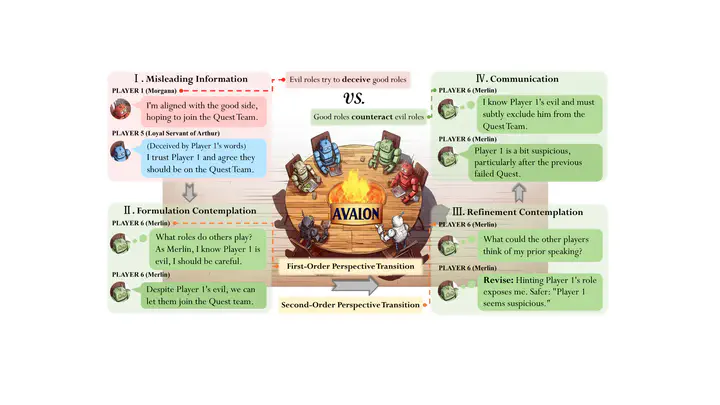 Framework of ReCon
Framework of ReConAbstract
Recent breakthroughs in large language models (LLMs) have brought remarkable success in the field of LLM-as-Agent. Nevertheless, a prevalent assumption is that the information processed by LLMs is consistently honest, neglecting the pervasive deceptive or misleading information in human society and AI-generated content. This oversight makes LLMs susceptible to malicious manipulations, potentially resulting in detrimental outcomes. This study utilizes the intricate Avalon game as a testbed to explore LLMs’ potential in deceptive environments. Avalon, full of misinformation and requiring sophisticated logic, manifests as a “Game-of-Thoughts”. Inspired by the efficacy of humans’ recursive thinking and perspective-taking in the Avalon game, we introduce a novel framework, Recursive Contemplation (ReCon), to enhance LLMs’ ability to identify and counteract deceptive information. ReCon combines formulation and refinement contemplation processes; formulation contemplation produces initial thoughts and speech, while refinement contemplation further polishes them. Additionally, we incorporate first-order and second-order perspective transitions into these processes respectively. Specifically, the first-order allows an LLM agent to infer others’ mental states, and the second-order involves understanding how others perceive the agent’s mental state. After integrating ReCon with different LLMs, extensive experiment results from the Avalon game indicate its efficacy in aiding LLMs to discern and maneuver around deceptive information without extra fine-tuning and data. Finally, we offer a possible explanation for the efficacy of ReCon and explore the current limitations of LLMs in terms of safety, reasoning, speaking style, and format, potentially furnishing insights for subsequent research.
The Arxiv link is https://arxiv.org/abs/2310.01320.
Shenzhi Wang
PhD Candidate of Artificial Intelligence
My research interests include reinforcement learning, LLM-as-agent, etc.