 GORL Framework
GORL FrameworkAbstract
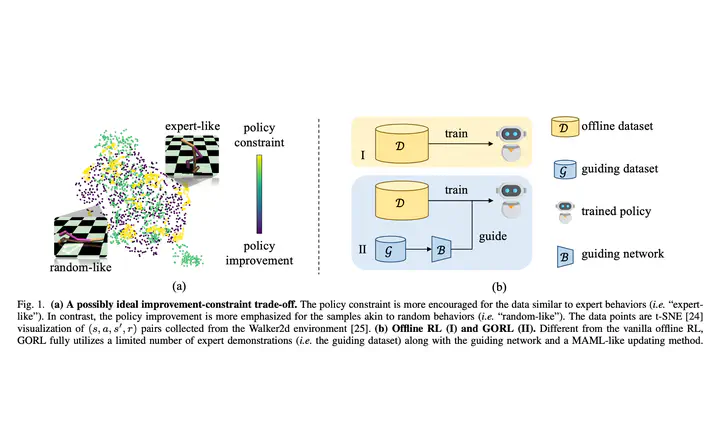
Offline reinforcement learning (RL) optimizes the policy on a previously collected dataset without any interactions with the environment, yet usually suffers from the distributional shift problem. To mitigate this issue, a typical solution is to impose a policy constraint on a policy improvement objective. However, existing methods generally adopt a “one-size-fits-all” practice, i.e., keeping only a single improvement-constraint balance for all the samples in a mini-batch or even the entire offline dataset. In this work, we argue that different samples should be treated with different policy constraint intensities. Based on this idea, a novel plug-in approach named Guided Offline RL (GORL) is proposed. GORL employs a guiding network, along with only a few expert demonstrations, to adaptively determine the relative importance of the policy improvement and policy constraint for every sample. We theoretically prove that the guidance provided by our method is rational and near-optimal. Extensive experiments on various environments suggest that GORL can be easily installed on most offline RL algorithms with statistically significant performance improvements.
The Arxiv link is https://arxiv.org/abs/2309.01448.
Shenzhi Wang
PhD Candidate of Artificial Intelligence
My research interests include reinforcement learning, LLMs, LLM-as-agent, etc.