Biography
I’m Shenzhi Wang (王慎执 in Chinese), a third-year Ph.D. student at LEAP Lab in the Department of Automation at Tsinghua University, advised by Prof. Shiji Song and Prof. Gao Huang. Before that, I received my B.E. degree (with honors) at SHENYUAN Honors College of Beihang University, majoring in Computer Science and Technology.
I am a strong advocate for open-source projects and have proudly released several popular LLMs, such as 🔥Llama3-8B-Chinese-Chat, 🔥Llama3-70B-Chinese-Chat, and 🔥Mistral-7B-v0.3-Chinese-Chat. Welcome to follow my HuggingFace account and use my opensourced models!
In my spare time, I write some Chinese tech blogs on Zhihu (知乎) and have 10k+ followers. Welcome to follow my Zhihu account!
Important: I am actively looking for a visiting student position for the Fall 2024 semester. If you have any available positions, I would be very interested. Please feel free to contact me via wangshenzhi99@gmail.com!
- Reinforcement Learning
- Large Language Models (LLMs)
- LLM-as-Agent
- Computer Vision
PhD Student in Artificial Intelligence, 2021 - Present
Department of Automation, Tsinghua University
B.Eng. in Computer Science and Technology, 2017 - 2021
SHENYUAN Honors College, Beihang University
News
- May 26, 2024 We have released a preprint paper, DiveR-CT (Diversity-enhanced Red Teaming with Relaxing Constraints); see this Arxiv link.
- May 26, 2024 We now introduce Mistral-7B-v0.3-Chinese-Chat, which is the first model fine-tuned specifically for Chinese and English users based on Mistral-7B-Instruct-v0.3! Full-parameter fine-tuned on a mixed Chinese-English dataset of ~100K preference pairs, the Chinese ability of our Mistral-7B-v0.3-Chinese-Chat is significantly better than Mistral-7B-Instruct-v0.3! Besides, our Mistral-7B-v0.3-Chinese-Chat has great performance in mathematics, roleplay, tool use, etc.
- May 16, 2024 Two papers (1 main conference and 1 findings) are accepted by ACL 2024!
- May 10, 2024 We have released Llama3-70B-Chinese-Chat! Full-parameter fine-tuned on a mixed Chinese-English dataset of ~100K preference pairs, its Chinese performance surpasses ChatGPT and matches GPT-4, as shown by C-Eval and CMMLU results.
- May 06, 2024 We have released Llama3-8B-Chinese-Chat-v2.1! Compared to v1, the training dataset of v2.1 is 5x larger (~100K preference pairs), and it exhibits significant enhancements, especially in roleplay, function calling, and math capabilities! Compared to v2, v2.1 surpasses v2 in math and is less prone to including English words in Chinese responses.
- Apr 22, 2024 We have released Llama3-8B-Chinese-Chat-v1, the first Chinese chat model specifically fine-tuned for Chinese through ORPO based on the Meta-Llama-3-8B-Instruct model. Compared to the original Meta-Llama-3-8B-Instruct model, our Llama3-8B-Chinese-Chat model significantly reduces the issues of “Chinese questions with English answers” and the mixing of Chinese and English in responses. Additionally, compared to the original model, our model greatly reduces the number of emojis in the answers, making the responses more formal.
- Feb 19, 2024 We have released a preprint paper, PsychoGAT (Psychological Game AgenTs); see this Arxiv link.
- Oct 20, 2023 Honered to receive the First-Class Comprehensive Scholarship for Graduate Students from Tsinghua University in 2023.
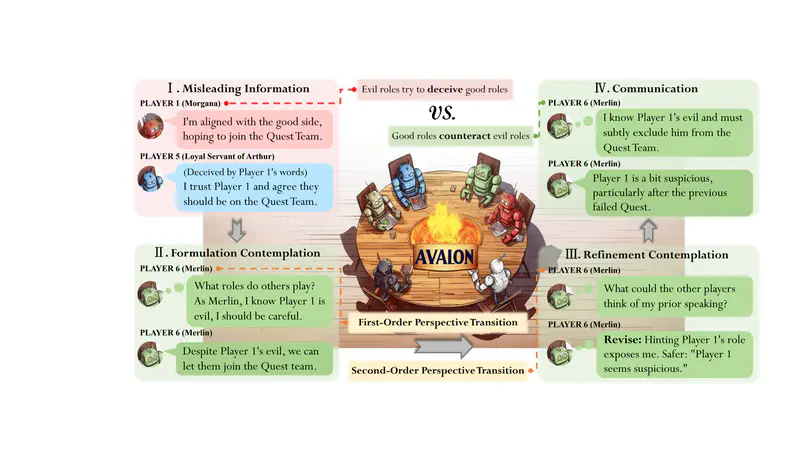
- Oct 02, 2023 We have released a preprint paper about LLMs dealing with deceptions in the Avalon game; see this Arxiv link.
- Sep 22, 2023 One paper is accepted by NeurIPS 2023 as Spotlight; see this Arxiv link.
- Jul 03, 2023 One paper is accepted by IEEE TNNLS!
- Apr 23, 2023 One paper is accepted by ICML 2023!
- Mar 01, 2021 One paper is accepted to CVPR 2021!
- Dec 09, 2020 Honored to be one of 21 undergraduates awarded SenseTime Scholarship, 2020.
Featured Publications
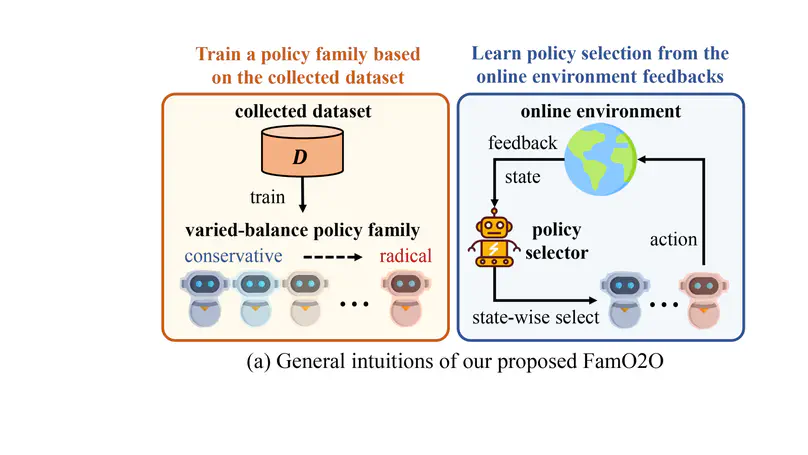
Publications
Academic Services
Reviewer for Conferences: NeurIPS (2023 & 2024), ICLR (2024), ICRA (2024), ACML (2024);
Reviewer for Journal: RA-L;
Reviewer for Workshop: ICLR 2024 AGI Workshop.
Contact
For more information about my work or to learn more about me, please don’t hesitate to reach out via email or in person.
- wangshenzhi99@gmail.com
- 616 Center Main Building, Tsinghua University, Beijing 100084, China.